如果说要对一个站点或者应用程序经常优化,可以说缓存的使用是最快也是效果最明显的方式。一般而言,我们会把一些常用的,或者需要花费大量的资源或时间而产生的数据缓存起来,使得后续的使用更加快速。
如果真要细说缓存的好处,还真是不少,但是在实际的应用中,很多时候使用缓存的时候,总是那么的不尽人意。换句话说,假设本来采用缓存,可以使得性能提升为100(这里的数字只是一个计量符号而已,只是为了给大家一个“量”的体会),但是很多时候,提升的效果只有80,70,或者更少,甚至还会导致性能严重的下降,这个现象在使用分布式缓存的时候尤为突出。
在本篇文章中,我们将为大家讲述导致以上问题的9大症结,并且给出相对应的解决方案。文章以.NET为例子进行代码的演示,对于来及其他技术平台的朋友也是有参考价值的,只要替换相对应的代码就行了!
为了使得后文的阐述更加的方便,也使得文章更为的完整,我们首先来看看缓存的两种形式:本地内存缓存,分布式缓存。
首先对于本地内存缓存,就是把数据缓存在本机的内存中,如下图1所示:
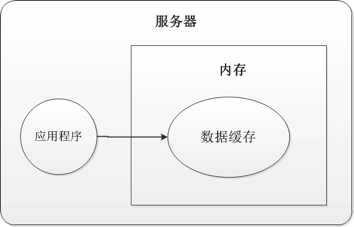
从上图中可以很清楚的看出:
对于分布式的缓存,此时因为缓存的数据是放在缓存服务器中的,或者说,此时应用程序需要跨进程的去访问分布式缓存服务器,如图2:
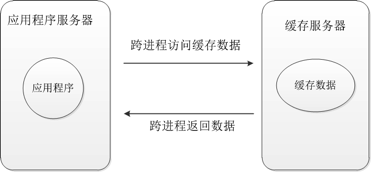
不管缓存服务器在哪里,因为涉及到了跨进程,甚至是跨域访问缓存数据,那么缓存数据在发送到缓存服务器之前就要先被序列化,当要用缓存数据的时候,应用程序服务器接收到了序列化的数据之后,会将之反序列化。序列化与反序列化的过程是非常消耗CPU的操作,很多问题就出现在这上面。
另外,如果我们把获取到的数据,在应用程序中进行了修改,此时缓存服务器中的原先的数据是没有修改的,除非我们再次将数据保存到缓存服务器。请注意:这一点和之前的本地内存缓存是不一样的。
对于缓存中的每一份数据,为了后文的讲述方面,我们称之为“缓存项“。
普及完了这两个概念之后,我们就进入今天的主题:使用缓存常见的9大误区:
上一篇:软件工程师必学的9件事
下一篇:软件开发模型